826.单链表
题目描述
实现一个单链表,链表初始为空,支持三种操作:
- 向链表头插入一个数;
- 删除第\(k\)个插入的数后面的数;
- 在第\(k\)个插入的数后插入一个数。
现在要对该链表进行\(M\)次操作,进行完所有操作后,从头到尾输出整个链表。
注意:题目中第\(k\)个插入的数并不是指当前链表的第\(k\)个数。例如操作过程中一共插入了\(n\)个数,则按照插入的时间顺序,这\(n\)个数依次为:第\(1\)个插入的数,第\(2\)个插入的数,第\(n\)个插入的数。
输入格式
第一行包含整数 \(M\),表示操作次数。
接下来\(M\)行,每行包含一个操作命令,操作命令可能为以下几种:
H x,表示向链表头插入一个数\(x\)。D k,表示删除第\(k\)个插入的数后面的数(当\(k\)为\(0\)时,表示删除头结点)。I k x,表示在第\(k\)个插入的数后面插入一个数\(x\)(此操作中\(k\)均大于\(0\))。
输出格式
共一行,将整个链表从头到尾输出。
数据范围
\(1 \leq M\leq 100000\)
所有操作保证合法。
输入样例
1 | |
输出样例
1 | |
代码
1 | |
本题思路分析
在本题中,第k个插入的元素位置到底在哪里?本题首先需要理解两个问题:
- 删除第
k个插入的数后面的数 - 在第
k个插入的数后面插入一个数
先解释一下什么叫第k个插入的元素:
- 把插入操作按先后排序,第
k次执行插入操作的那个元素。 - 注意:并不是链表中从前往后数第
k个元素。
在链表中删除指针指向的元素的后一个元素,或者在指针指向的某个元素后面插入一个新元素是很容易实现的。所以,只要弄明白第k个插入的数的指针在哪里,这两个问题就很容易解决。
来分析一下插入操作:
- 链表为空的时候:
idx的值为0, - 插入第一个元素
a后:e[0] = a,idx的值变为1, - 插入第二个元素
b后:e[1] = b,idx的值变为2, - 插入第三个元素
c后:e[2] = c,idx的值变为3,
所以:第k个出入元素的索引值k - 1。
有人会说,如果中间删除了某些元素呢?
在看一下伴随着删除操作的插入:
- 链表为空的时候:
idx的值为0, - 插入第一个元素
a后:e[0] = a,idx的值变为1, - 插入第二个元素
b后:e[1] = b,idx的值变为2, - 删除第一个插入的元素
a:head变为1,idx不变,依旧为2。 - 删除第二个插入的元素
b:head变为2,idx不变,依旧为2。 - 插入第三个元素
c后:e[2] = c,idx的值变为3。
所以删除操作并不改变第k个插入元素的索引。故第k个元素的索引一定是k - 1。
对于本题输入样例:
1 | |
我们给出操作图示:
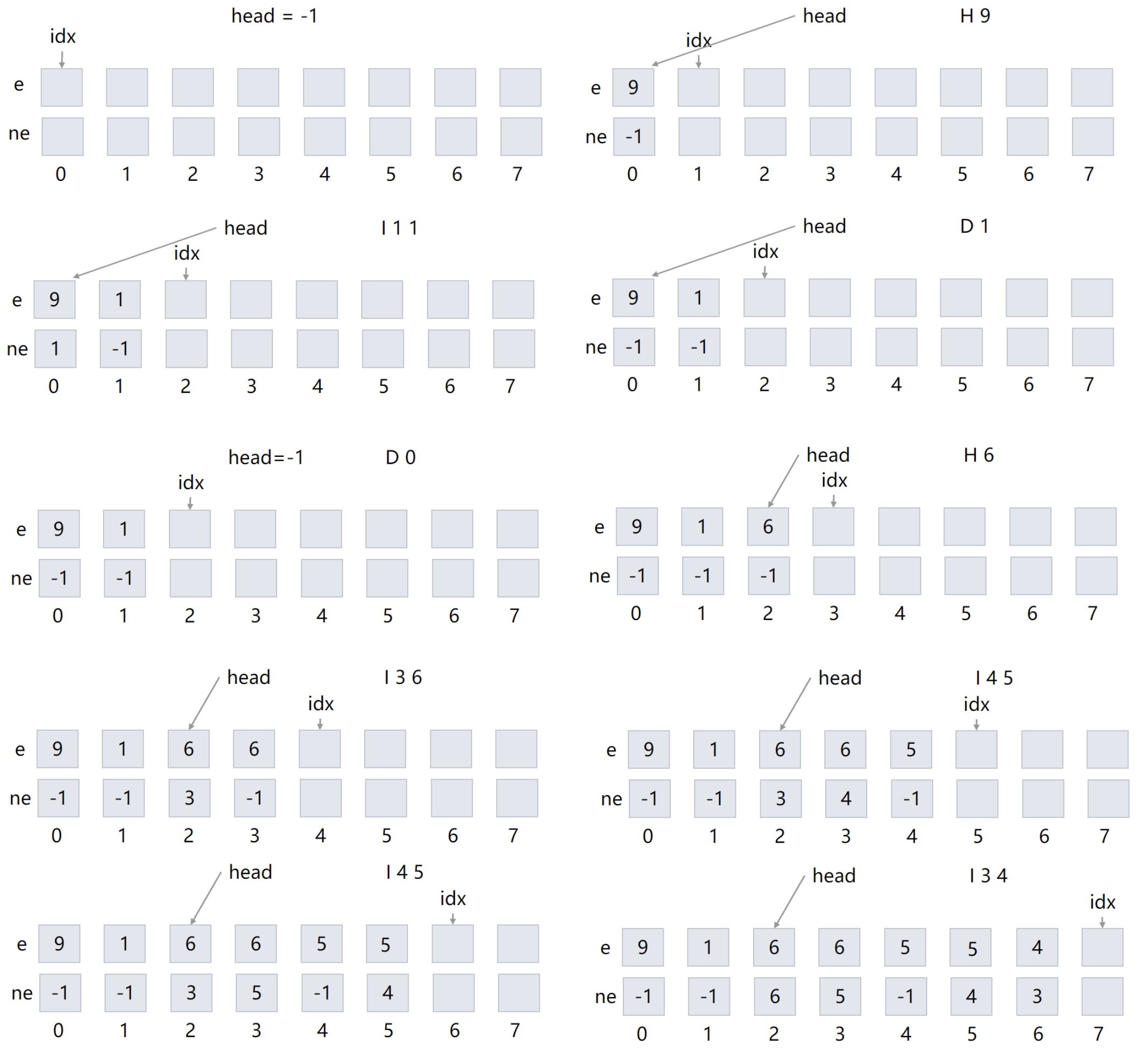
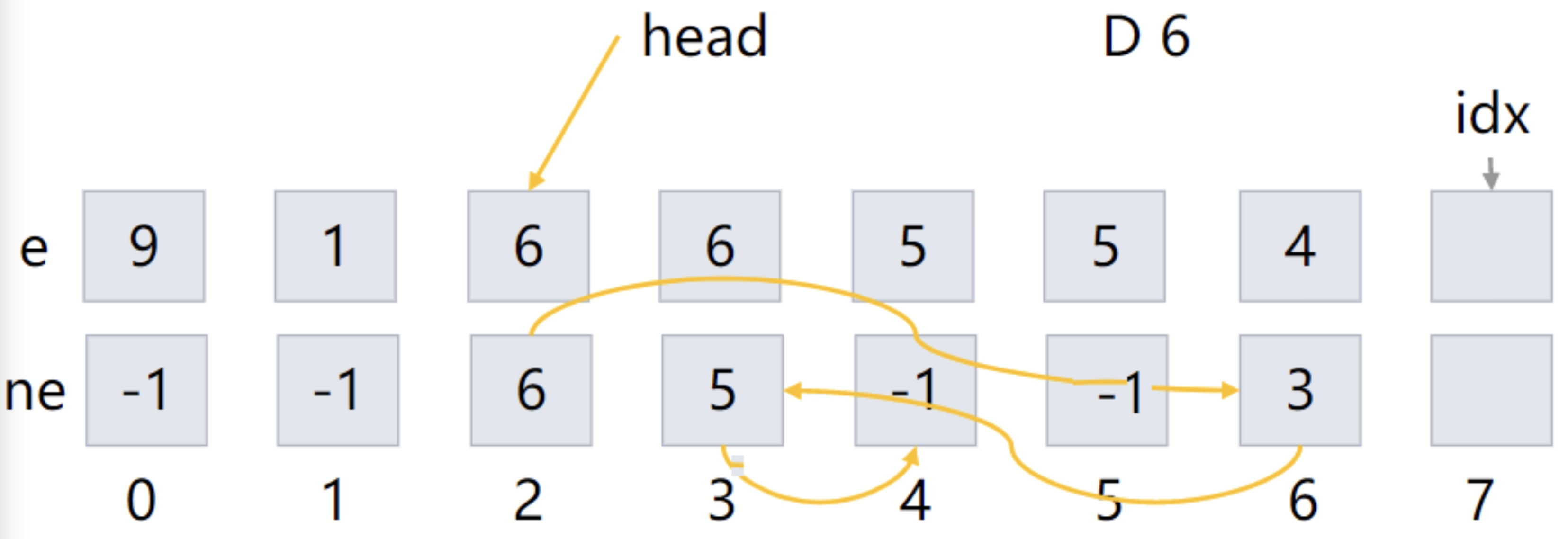
最终链表结果如图:
1 | |
单链表知识点问题汇总
1. head是什么?它的具体作用又是啥?
head应该是一个特殊的指针,一开始指向-1,表示链表里没有内容,为空节点,当链表里有元素的时候,它变成了一个指向第一个元素的指针。还有就是为了最后遍历链表时,知道链表什么时候结束(因为最后实现的链表,它最后一个节点的ne[i]一定等于-1)
2. 对于k-1的相关问题?
这个函数含义是将x插到下标是k的点后面。题目里要将x插入到第k个插入的数后面,第k个插入的数下标是k - 1,所以调用的时候是add(k - 1, x)和remove(k - 1)。如果你一开始将idx = 1(初始化),那么下标和k就统一了,就不需要再k - 1了。
3. 关于e[idx]、ne[idx]和idx的问题?
idx可以理解为一个结点!!准确来说是某个结点的唯一标识,也是链表中结点的索引下标。
结点:链表的元素,含e[idx],ne[idx]两个部分:
e[idx]:结点编号为idx对应的节点值ne[idx]:结点编号为idx对应的下一个结点的编号
要明白idx只是记录当前的操作的位置,一般实现的链表idx是乱序的(前后的节点的数组下标不需要连续【不理解,可以带入样例观察】),需要通过当前的ne[i]找到下一个idx。这也是两者的联系。
4. 对于删除头节点:head=ne[head]的操作?
删除头结点是head指向的结点,也就是链表中的第一个结点,head指向可能是一个空结点(e数组不存值),或者是非空结点。指向空结点的叫头结点,指向非空结点的叫首元结点。但是y总并没有区分这个概念,所以删除头结点就是删除链表的第一个有值的结点,head指向ne[head]是因为head本来就指向它的下一个结点,所以ne[head]就是头结点的下一个结点。
5.
为什么最后一个节点的ne[idx]一定等于-1?
首先这个head指的是链表中头节点的下标,当链表中没有节点时head = -1,但当链表中有值插到头节点的时候,head储存的就是这个值的idx,通过e[idx]可以求出这个节点的值。而ne[idx]就等于head之前的值,即-1。如果再在头节点插入一个元素,则head指向这个元素的idx2,而ne[idx2]就等于上一次插入的head值,即idx。此时,head = idx2,ne[idx2] = idx,ne[idx] = -1。
比如:因为初始化head = -1,head指向链表的头节点地址;例如输入H 9后,则有:
1 | |
之后无论进行什么操作,链表最后一个节点,其对应的ne数组值一定为-1。
6.
为什么每次循环输入的字符op,用cin >> op可以ac,而scanf("%c", &op)结果就不行?
这个是分情况的。有一个特殊的格式%c,当%c格式的时候,会读取任何字符,包括换行和空格。当其他格式的时候(不包括正则表达式),如果空格或者换行出现在前面,会被读取并抛弃。在后面的时候,不会读取,而只是检测。
其实这里也可以写成scanf(" %c", &op)【%c前面要加空格】,以过滤空格和回车。
7. head = idx++ 等价于
head=idx, idx++
8. 根据1、3和5应该也就不难理解这句话了吧
1 | |
9. 为何不用结构体方式构造链表?
链表由节点构成,每个节点保存了值和下一个元素的位置这两个信息。节点的表示形式如下:
1 | |
这样构造出链表节点的是一个好方法,也是许多人一开始就学到的。使用这种方法,在创建一个值为x新节点的时候,语法是:
1 | |
看一下创建新节点的代码的第一行:
1 | |
中间有一个new关键字来为新对象分配空间。new的底层涉及内存分配,调用构造函数,指针转换等多种复杂且费时的操作。在平时的工程代码中,不会涉及上万次的new操作,所以这种结构是一种见代码知意的好结构。
但是在算法比赛中,经常碰到操作在10万级别的链表操作,如果使用结构体这种操作,是无法在算法规定时间完成的。所以,在算法比赛这种有严格的时间要求的环境中,不能频繁使用new操作。也就不能使用结构体来实现数组。